探索 RL 问题#
Jetbot 的控制命令是一个单位向量,用来指定期望的驾驶方向,我们必须以某种方式使智能体感知到这一点,以便根据情况调整操作。有许多可能的方法可以做到这一点,简单的方法是改变观测空间,将该控制命令包含在其中。首先, 编辑 ``IsaacLabTutorialEnvCfg`` 将观测空间设置为 9 : 世界速度向量包含机器人的线性和角速度,这是 6 维,如果我们将控制命令附加到这个向量中,那就是观测空间总共有 9 维。
接下来,我们只需要在获取观测时进行附加。我们还需要计算以后使用的前进向量。Jetbot 的前进向量是 x 轴,因此我们将 root_link_quat_w 应用于 [1,0,0] 以获得世界坐标系中的前进向量。将 _get_observations 方法替换为以下内容:
def _get_observations(self) -> dict:
self.velocity = self.robot.data.root_com_vel_w
self.forwards = math_utils.quat_apply(self.robot.data.root_link_quat_w, self.robot.data.FORWARD_VEC_B)
obs = torch.hstack((self.velocity, self.commands))
observations = {"policy": obs}
return observations
那么现在应该奖励什么呢?
当机器人表现如期望的那样时,它将全速朝着控制命令的方向行驶。如果我们奖励 "前进" 和 "与控制命令对齐" ,那么最大化这两者的组合信号应该导致机器人朝着控制命令前进... 对吗?
让我们试试吧!将 _get_rewards 方法替换为以下内容:
def _get_rewards(self) -> torch.Tensor:
forward_reward = self.robot.data.root_com_lin_vel_b[:,0].reshape(-1,1)
alignment_reward = torch.sum(self.forwards * self.commands, dim=-1, keepdim=True)
total_reward = forward_reward + alignment_reward
return total_reward
forward_reward 是机器人质心线性速度在机体坐标系中的 x 分量。我们知道 x 方向是资产的前进方向,因此这应等同于前进向量与世界坐标系中线性速度的内积。对齐项是前进向量与控制命令向量的内积: 当它们指向同一方向时,这一项将为 1,但指向相反方向时,它将为 -1。将它们相加以获得组合奖励,最后我们可以开始训练了!让我们看看会发生什么!
python scripts/skrl/train.py --task=Template-Isaac-Lab-Tutorial-Direct-v0
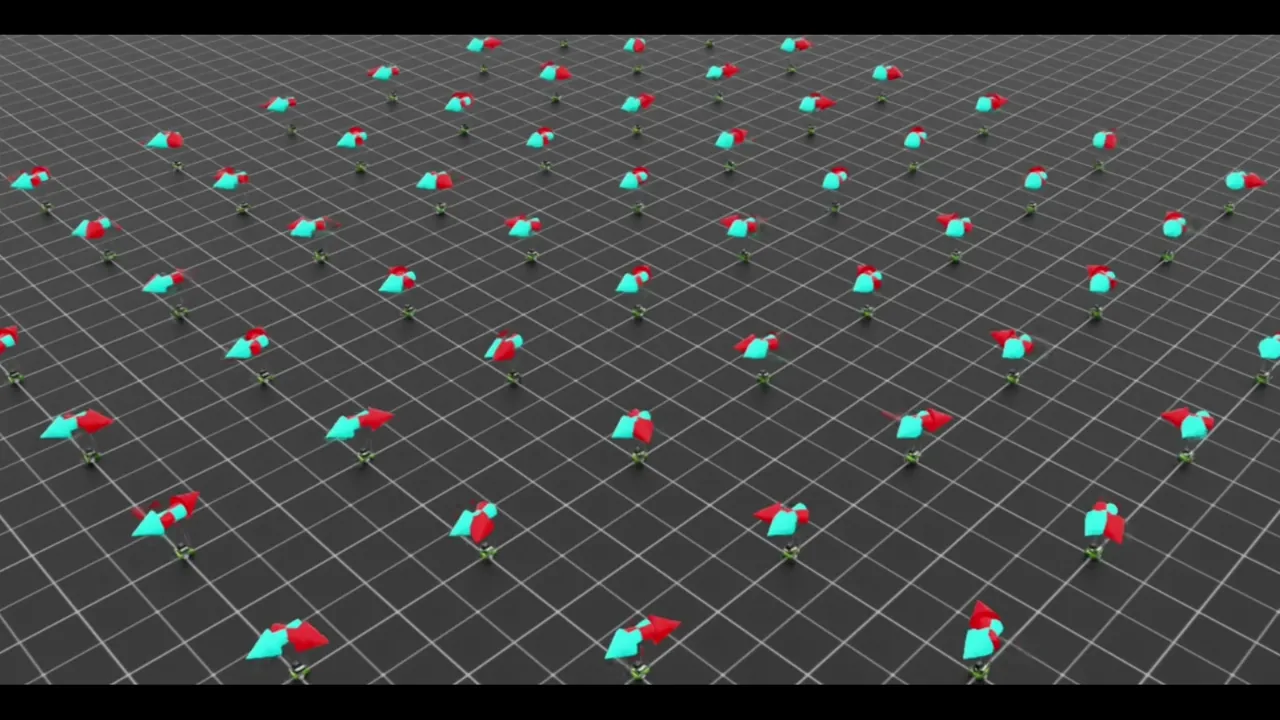
我们肯定可以做得更好!
奖励和观测调整#
当为训练调整环境时,一个经验法则是尽可能保持观测空间尽可能小。这是为了减少模型中的参数数量(奥卡姆剃刀的字面解释),从而改善训练时间。在这种情况下,我们需要以某种方式对与控制命令的对齐和前进速度进行编码。一种方法是利用线性代数中的点积和叉积!用以下内容替换 _get_observations 的内容:
def _get_observations(self) -> dict:
self.velocity = self.robot.data.root_com_vel_w
self.forwards = math_utils.quat_apply(self.robot.data.root_link_quat_w, self.robot.data.FORWARD_VEC_B)
dot = torch.sum(self.forwards * self.commands, dim=-1, keepdim=True)
cross = torch.cross(self.forwards, self.commands, dim=-1)[:,-1].reshape(-1,1)
forward_speed = self.robot.data.root_com_lin_vel_b[:,0].reshape(-1,1)
obs = torch.hstack((dot, cross, forward_speed))
observations = {"policy": obs}
return observations
我们还需要 修改 ``IsaacLabTutorialEnvCfg`` 以将观测空间设置回3 ,这包括点积、叉积的z分量和前向速度。
点积或内积告诉我们两个向量对齐程度的单一标量量。如果它们非常对齐并指向相同方向,那么内积将很大且为正,但如果它们对齐且方向相反,则内积将很大且为负。如果两个向量垂直,内积为零。这意味着前进向量和控制命令向量之间的内积可以告诉我们朝向控制命令还是背离控制命令的程度,但不能告诉我们需要向哪个方向转动以改善对齐。
叉乘也告诉我们两个向量的对齐程度,不过它将这种关系表示为向量。任意两个向量之间的叉乘定义了一个垂直于包含两个参数向量的平面的轴,其中结果向量沿此轴的方向由坐标系的手征性(维度排序或右手性)确定。在我们的情况中,我们可以利用我们在 2D 中操作的事实,只需要检查 \(\vec{forward} \times \vec{command}\) 的结果的 z 分量。如果向量共线,这一分量将为零,如果控制命令向量位于前方,则为正,如果控制命令向量位于前方的右侧,则为负。
最后,质心线性速度的 x 分量告诉我们我们的前进速度,正数表示前进,负数表示后退。我们将这些 "水平" 叠加在一起(沿 dim 1)以生成每个 Jetbot 的观测。这样单独就能提高性能!
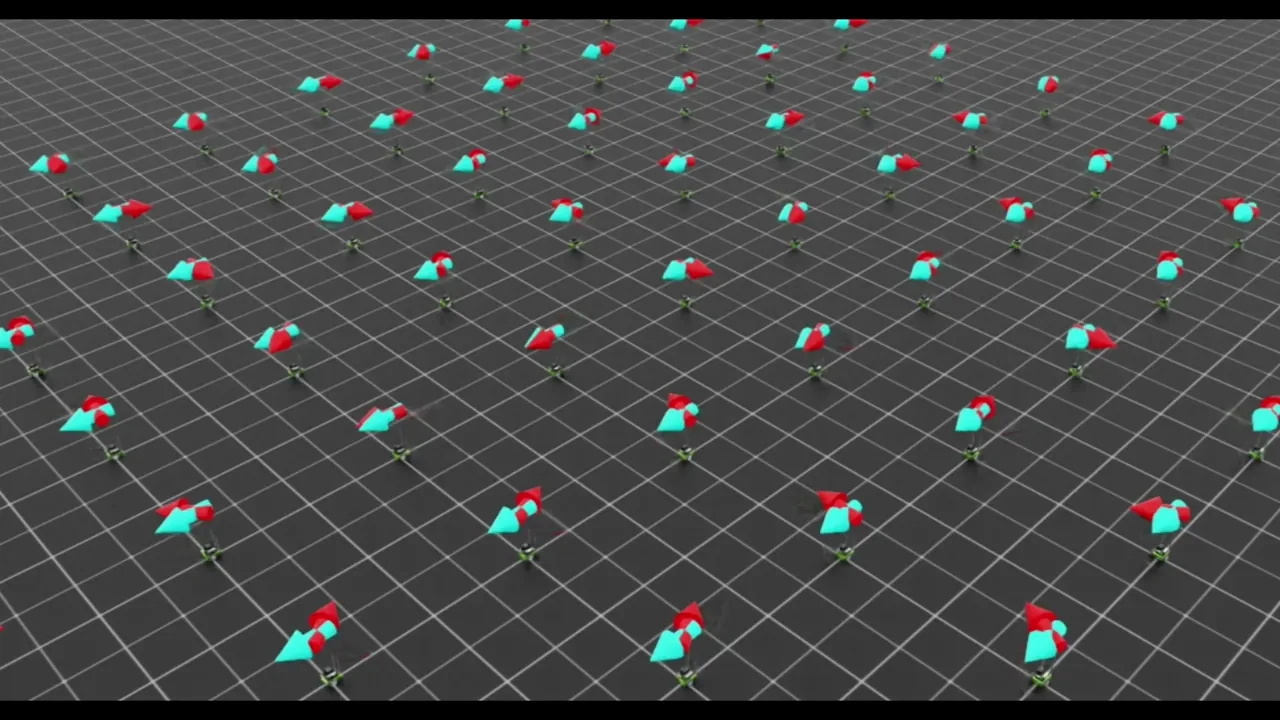
在质量上训练效果更好,Jetbots 有些许向前移动... 我们肯定还可以做得更好!
训练的另一个经验法则是尽可能减少和简化奖励函数。奖励函数中的术语类似于逻辑的 "OR" 运算。在我们的情况下,我们通过将它们相加来奖励前进和对齐控制命令,这样我们的智能体就可以获得同等奖励来前进或对齐控制命令。为了强迫智能体学会朝着控制命令的方向前进,我们应该仅奖励智能体前进且对齐。逻辑的 AND 意味着乘法,因此下面是奖励函数:
def _get_rewards(self) -> torch.Tensor:
forward_reward = self.robot.data.root_com_lin_vel_b[:,0].reshape(-1,1)
alignment_reward = torch.sum(self.forwards * self.commands, dim=-1, keepdim=True)
total_reward = forward_reward*alignment_reward
return total_reward
现在我们只有在对齐奖励为非零时才会因前进而获得奖励。让我们看看这会产生怎样的结果!

训练速度确实更快了,但如果控制命令指向它们后面,Jetbots 已经学会后退驾驶。在我们的情况中,这可能是令人满意的,但这也展示了政策行为如何高度取决于奖励函数。在这种情况下,我们的奖励函数存在 退化解 : 驾驶前进并与控制命令对齐时奖励最大化,但如果 Jetbot 在倒车,那么前进项为负数,如果它朝着控制命令后退,那么对齐项 也为负数 ,这意味着奖励是正数!当您设计自己的环境时,您会遇到像这样的退化解,并且大量奖励工程任务就是通过修改奖励函数来抑制或支持这些行为。
假设在我们的情况下,我们不希望出现这种行为。在我们的情况中,对齐项的定义域是 [-1, 1] ,但我们更希望它仅映射到正值。我们不希望 消除 对齐项上的符号,相反,我们希望大负值接近零,这样当我们不对齐时就不会得到奖励。指数函数可以实现这一点!
def _get_rewards(self) -> torch.Tensor:
forward_reward = self.robot.data.root_com_lin_vel_b[:,0].reshape(-1,1)
alignment_reward = torch.sum(self.forwards * self.commands, dim=-1, keepdim=True)
total_reward = forward_reward*torch.exp(alignment_reward)
return total_reward
现在当我们进行训练时,Jetbots 将始终朝着控制命令以前进方向前进!